Scan a paper document to PDF and use Acrobat to turn it into a smart, searchable PDF with selectable text.
Scan a paper document to PDF and use Acrobat to turn it into a smart, searchable PDF with selectable text.
You can create a PDF file directly from a paper document, using your scanner and Acrobat. On Windows, Acrobat supports TWAIN scanner drivers and Windows Image Acquisition (WIA) drivers. On Mac OS, Acrobat supports TWAIN and Image Capture (ICA).
In Windows, you can either use the Autodetect Color Mode and let Acrobat determine the paper document’s content type, or use other presets (Black & White Document, Grayscale Document, Color Image, and Color Document) based on your judgment. You can configure the scanning presets or use the Custom Scan option to scan with the settings of your choice.
Note:
Preset scanning is available only for scanner drivers that support Hide Scanner’s Native Interface mode. The scanning presets are not available on Mac OS.
In Windows, if a WIA driver is installed for your scanner, you can use the Scan button on your scanner to create a PDF. Press the Scan button, and then in Windows, choose Adobe Acrobat from the list of registered applications. Then, in the Acrobat scan interface, select a scanner and a document preset or Custom Scan.
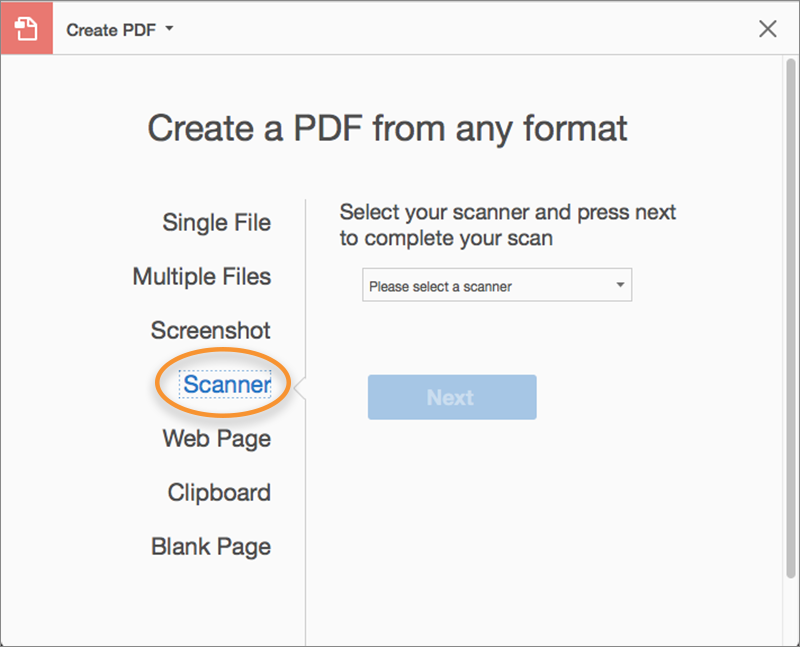
To scan a paper document to PDF using Acrobat, go to Tools > Create PDF. The Create a PDF from any format interface is displayed. Choose Scanner to see the options available.


Note:
If you want to append the document, which you’ll scan, to an existing file, do the following:
Note:
If you want to append the document, which you’ll scan, to an existing file, do the following:
Note:
If you want to append the document, which you’ll scan, to an existing file, do the following:
If you want to change the settings, click the Settings ![]() icon. The Custom Scan interface is displayed. Select scanning options as needed.
icon. The Custom Scan interface is displayed. Select scanning options as needed.
If you want to scan multiple files into a PDF, select the Prompt to scan more pages check box.
Note:
If you specify that you want to use the Show scanner’s user interface instead of the Acrobat user interface, other windows or dialog boxes appear. Consult the scanner documentation information on available options. In Mac OS, the scanner user interface is always shown.
Select options in the Secondary toolbar – click the Settings ![]() icon and choose appropriate options in the Enhance Scanned PDF dialog box, and click OK.
icon and choose appropriate options in the Enhance Scanned PDF dialog box, and click OK.
For more information on the options displayed in the dialog box, see Enhance Scanned PDF dialog box.
After you select a scanner, you can choose or adjust its various scanning options as per your requirements.
The Enhance Scanned PDF dialog box controls the image settings of how scanned images are filtered and compressed for the PDF. Default settings are suitable for a wide range of document pages, but you may want to customize settings for higher-quality images, smaller file sizes, or scanning issues.
Document Language
By default the OCR language is picked from default locale. To change the language, click Edit and choose a different language.
For troubleshooting tips, see Troubleshoot scanner issues when scanning using Acrobat.
You can use Acrobat to recognize text in previously scanned documents that have already been converted to PDF. Optical character recognition (OCR) software enables you to search, correct, and copy the text in a scanned PDF. To apply OCR to a PDF, the original scanner resolution must have been set at 72 dpi or higher.
Note:
Scanning at 300 dpi produces the best text for conversion. At 150 dpi, OCR accuracy is slightly lower.
Output (PDF Output Style)
Determines the type of PDF to produce. All options require an input resolution of 72 dpi or higher (recommended). All formats apply OCR and font and page recognition to the text images and convert them to normal text.
Downsample To
Decreases the number of pixels in color, grayscale, and monochrome images after OCR is complete. Choose the degree of downsampling to apply. Higher-numbered options do less downsampling, producing higher-resolution PDFs.
When you run OCR on a scanned output, Acrobat analyzes bitmaps of text and substitutes words and characters for those bitmap areas. If the ideal substitution is uncertain, Acrobat marks the word as suspect. Suspects appear in the PDF as the original bitmap of the word, but the text is included on an invisible layer behind the bitmap of the word. This method makes the word searchable even though it is displayed as a bitmap.
Note: If you try to select text in a scanned PDF that does not have OCR applied, or try to perform a Read Out Loud operation on an image file, Acrobat asks if you want to run OCR. If you click OK, the Text Recognition dialog box opens and you can select options, which are described in detail under the previous topic.
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry’s standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book.
Countrywide Process
June 18, 2019